Si bien bajar los datos del IPC que entrega el INE mensualmente y hacer una tabla dinámica no toma más de un par de minutos, a la larga es un ejercicio tedioso y repetitivo.
A continuación te mostramos cómo hacemos en Pacífico Research para generar una metodología que permita automatizar este proceso, además de facilitar modificaciones para realizar análisis ad-hoc a la coyuntura cambiante.
Primero, importaremos la base de datos del IPC del Instituto Nacional de Estadísticas (INE).
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as mtickurl='https://www.ine.cl/docs/default-source/%C3%ADndice-de-precios-al-consumidor/cuadros-estadisticos/base-2018/series-de-tiempo/ipc-xls.xlsx'df_INE=pd.read_excel(url,skiprows=3)Ahora filtramos solamente productos, ya que éstos son el nivel más desagregado que publica el INE y creamos un ID único a cada producto. La ventaja de trabajar con un ID numérico sobre un nombre (por ejemplo: “Paquete Turístico”) es que evitamos problemas asociados a la tipografía (espacios, tildes, mayúsculas, etc.). Con este paso, evitamos cualquier tipo de error. Además, cambiaremos la base de tipo “long” a “wide” con la función pivot_table, que es análoga a su contraparte tabla dinámica de MS Excel.
def genera_ID(dataframe,columnas_DGCSP):
"""Genera un ID único para cada producto a partir de su número de división, grupo, clase, subclase y producto"""
ID=(
dataframe[columnas_DGCSP[0]]*1e5+
dataframe[columnas_DGCSP[1]]*1e4+
dataframe[columnas_DGCSP[2]]*1e3+
dataframe[columnas_DGCSP[3]]*1e2+
dataframe[columnas_DGCSP[4]]*1e0
).astype(int)
return IDfiltro_productos=df_INE['Producto'].astype(str).str.isnumeric()df_productos=df_INE[filtro_productos]
df_productos['Fecha']=df_productos['Año']*1e4+df_productos['Mes']*1e2+1
df_productos['Fecha']=pd.to_datetime(df_productos['Fecha'],format='%Y%m%d')
columnas_DGCSP=['División','Grupo','Clase','Subclase','Producto']
df_productos['ID']=genera_ID(df_productos,columnas_DGCSP)df_productos_mensuales=df_productos.pivot_table(values='Índice',index='ID',columns='Fecha')Por otro lado, rescataremos los ponderadores de cada producto. Para esto fijaremos arbitrariamente un mes en específico y tomaremos esta información, ya que actualmente está replicada por cada nuevo mes que se agrega en la base.
filtro_mes=df_productos['Fecha']==df_productos['Fecha'].iloc[0]df_auxiliar_ponderadores=df_productos[['Fecha','Ponderación','ID']][filtro_mes]
df_auxiliar_ponderadores.index=df_auxiliar_ponderadores['ID']
ponderadores=df_auxiliar_ponderadores.sort_index()['Ponderación']Con la base en formato wide (tipo tabla dinámica) y los ponderadores podemos crear una función que tome estos dos inputs y calcule el nivel del índice. Luego, a partir de estos niveles, podemos concentrarnos en variaciones mensuales, interanuales o de otra naturaleza.
def calcula_índice(dataframe,ponderadores):
"""Regresa el nivel de cualquier índice"""
numerador=dataframe.mul(ponderadores.values,axis=0).sum()
denominador=ponderadores.sum()
niveles=numerador/denominador
return nivelesniveles_IPC=calcula_índice(df_productos_mensuales,ponderadores)
variacion_mensual_IPC=niveles_IPC.pct_change(1)[1:]
variacion_anual_IPC=niveles_IPC.pct_change(12)[12:]fig = plt.figure()
ax = fig.add_subplot(1,1,1)
colors = ['g' if var_mensual > 0 else 'r' for var_mensual in variacion_mensual_IPC.values]
plt.bar(variacion_mensual_IPC.index,variacion_mensual_IPC.values,width=20,color=colors)
plt.xlabel('Fecha')
plt.title ('Inflacion Mensual')
plt.xticks(rotation=45)
ax.yaxis.set_major_formatter(mtick.PercentFormatter(1))
plt.show()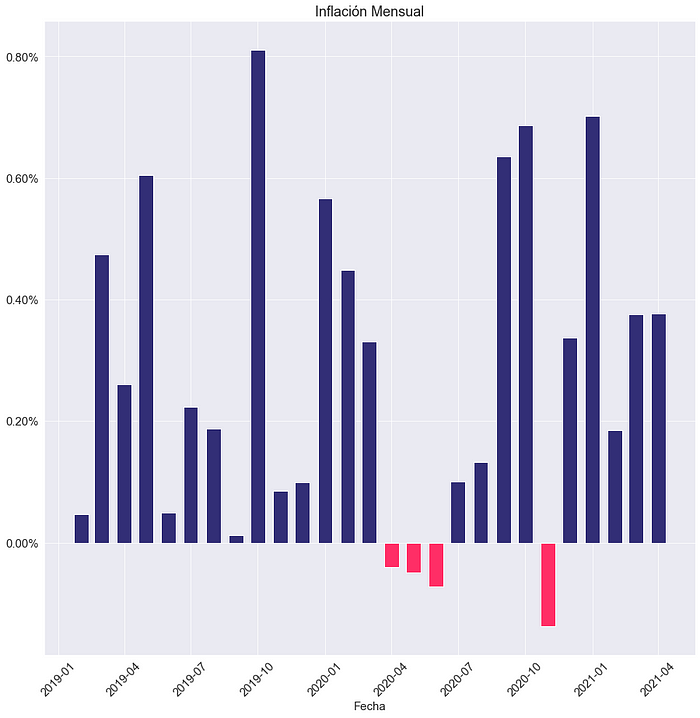
De la misma manera en que replicamos el Índice General del IPC, podemos replicar sus índices analíticos cambiando el input de ponderadores. Por ejemplo, replicando el Índice de Precios al Consumidor Sin Alimentos ni Energía (IPC SAE).
url_ponderadores='https://www.ine.cl/docs/default-source/%C3%ADndice-de-precios-al-consumidor/metodologias/base-anual-2018-100/canasta-anal%C3%ADticos-ipc-2018=100.xlsx'df_ponderadores=pd.read_excel(url_ponderadores,skiprows=1)
df_ponderadores['ID']=genera_ID(df_ponderadores,['D','G','C','SC','P'])df_ponderadores.sort_values('ID',inplace=True)filtro_SAE=df_ponderadores['IPC menos Alimentos y Energía']
ponderadores_SAE=ponderadores*filtro_SAE.values
niveles_IPC_SAE=calcula_indice(df_productos_mensuales,ponderadores_SAE)
variacion_mensual_IPC_SAE=niveles_IPC_SAE.pct_change(1)[1:]
variacion_anual_IPC_SAE=niveles_IPC_SAE.pct_change(12)[12:]fig = plt.figure()
ax = fig.add_subplot(1,1,1)
colors = ['g' if var_mensual > 0 else 'r' for var_mensual in variacion_mensual_IPC_SAE.values]
plt.bar(variacion_mensual_IPC_SAE.index,variacion_mensual_IPC_SAE.values,width=20,color=colors)
plt.xlabel('Fecha')
plt.title ('Inflacion Mensual SAE')
plt.xticks(rotation=45)
ax.yaxis.set_major_formatter(mtick.PercentFormatter(1))
plt.show()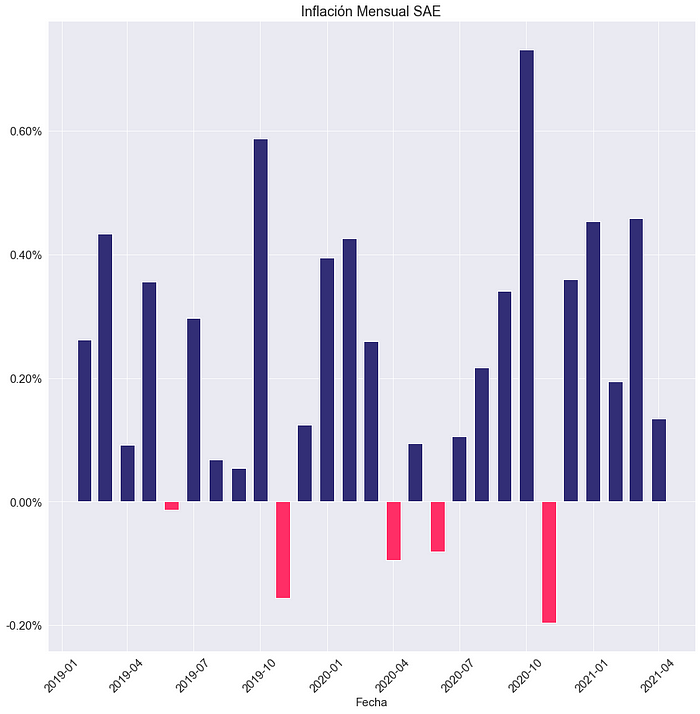
Hasta ahora sólo hemos replicado el cálculo de productos a índice general del INE. Una posible acción adicional sería a continuación cambiar el input de la base y agregar supuestos sobre el comportamiento futuro de los productos del índice, para proyectar qué pasará con el índice general. Esto es lo que hacemos en Pacífico Research.
Otro ejercicio sería modificar los ponderadores y crear un índice personalizado, dependiendo del análisis que se quiera realizar. En el último tiempo, por motivos de la pandemia, una serie de servicios sufrió una baja abrupta en su oferta, siendo los más destacados para motivos del análisis de precios “Servicio de Transporte Aéreo” y “Paquete Turístico”. El INE optó metodológicamente por imputar estos productos por el método de arrastre (mantener el último valor recogido, en este caso, abril del 2020). ¿Qué hubiese pasado hipotéticamente si el INE hubiese removido estos productos del indicador, en vez de imputarlos?
ponderadores_personalizado=ponderadores.copy()
ponderadores_personalizado[732101]=0 #"Servicio de Transporte Aéreo"
ponderadores_personalizado[951101]=0 #"Paquete Turístico"Es importante destacar que usamos que una ponderación de 0 es equivalente a una exclusión del producto. Luego eliminamos un producto mediante su ID, por ejemplo, “Servicio de Transporte Aéreo” que es el primer producto de la primera subclase de la primera clase del quinto grupo de la séptima división.
niveles_IPC_personalizado=calcula_indice(df_productos_mensuales,ponderadores_personalizado)
variacion_mensual_IPC_personalizado=niveles_IPC_personalizado.pct_change(1)[1:]
variacion_anual_IPC_personalizado=niveles_IPC_personalizado.pct_change(12)[12:]fig = plt.figure()
ax = fig.add_subplot(1,1,1)
plt.plot(variacion_anual_IPC,label='IPC',linewidth=3)
plt.plot(variacion_anual_IPC_personalizado, label='IPC_sin_TA_PT',linewidth=3)
plt.axhline(y=0.03, label='Meta Bcentral', color='r')
plt.xlabel('Fecha')
plt.xticks(rotation=45)
plt.title ('Inflacion Anual sin Transporte Aereo ni Paquete Turistico')
plt.legend()
ax.yaxis.set_major_formatter(mtick.PercentFormatter(1))
plt.show()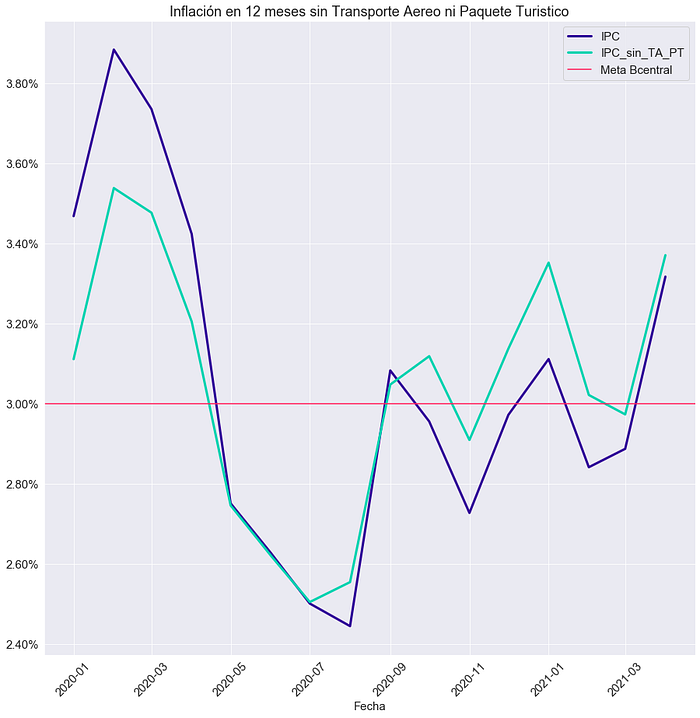
diferencias=(niveles_IPC_personalizado.pct_change(12)-niveles_IPC.pct_change(12))[15:]
diferencias.abs().max()0.002405380212629149Se encuentran hasta 0.24 décimas de diferencia de inflación interanual, si esos dos productos hubiesen sido removidos en vez de imputados por arrastre. ¿Qué hubiera pasado si en vez de una imputación por arrastre se hubiese usado otro tipo de metodología? ¿Cómo se ha comportado el IPC sin volátiles (la nueva medida subyacente que mira el Banco Central)? Ésas y otras preguntas quedan al lector (hint: pueden responderse fácilmente cambiando los inputs respectivos).
Encuentra este artículo en nuestra página de MEDIUM www.pacificoresearch.medium.com