Por Cristóbal Cortínez, Quant en Pacífico Research
La API de Pacífico contiene algunos algoritmos pre-implementados, entre ellos, una versión modificada de Análisis de Componentes Principales (PCA por sus siglas en inglés) aplicado a la curva de tasas forward chilena. Este algoritmo nos permite aproximar un conjunto dado por la suma ponderada de unos pocos componentes, lo que facilita enormemente los análisis posteriores.
El siguiente artículo muestra una versión simplificada de este análisis.
La curva de tasas es importante para poner precio a varios productos financieros. Sin embargo, visualizar su evolución a lo largo del tiempo, puede resultar una tarea difícil.
Para ilustrar esto, vamos a escribir un código en Python. Empecemos por importar las librerías que necesitaremos durante el resto del artículo.
from sklearn.decomposition import PCA
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.ticker import PercentFormatter
import pandas as pd
import numpy as npSupongamos que disponemos de curvas de tasas forward a 1 año del mercado chileno para varias fechas en un dataframe en formato largo:
dfRatesLong.tail(20)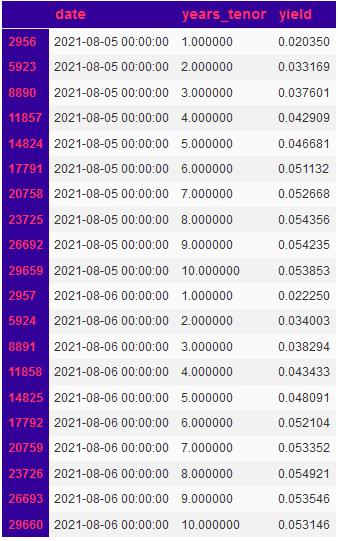
Intentemos graficar curvas para varias fechas:
dfPlot = dfRatesLong[dfRatesLong.date > "2021-07-15"]
dfPlot["date"] = dfPlot.date.apply(lambda d: d.date())
g = sns.lineplot(data=dfPlot,
x="years_tenor",
y="yield",
hue="date")
_ = g.yaxis.set_major_formatter(PercentFormatter(1))
_ = g.set_title("Chilean Forward Curves")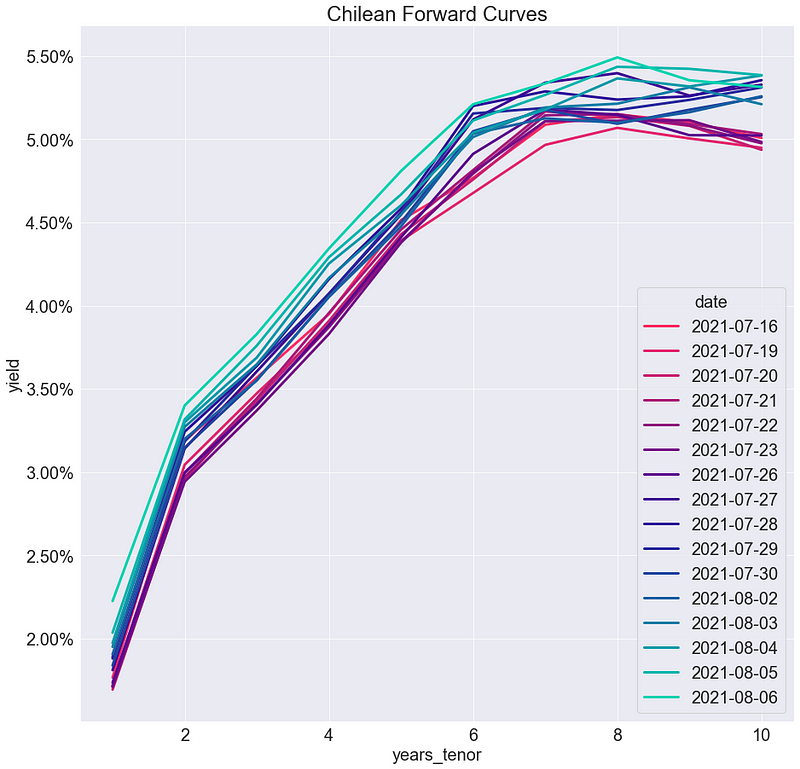
No se aprecia adecuadamente la evolución, además de que el gráfico se vuelve rápidamente incomprensible si se grafican demasiadas curvas.
Alternativamente, podemos graficar la trayectoria de las tasas con respecto al tiempo, para distintos tenors:
g = sns.lineplot(data=dfRatesLong,
x="date",
y="yield",
hue="years_tenor")
_ = g.yaxis.set_major_formatter(PercentFormatter(1))
_ = g.set_title("Chilean Forward Curves")
_ = [tick.set_rotation(30)
for tick in g.get_xticklabels()]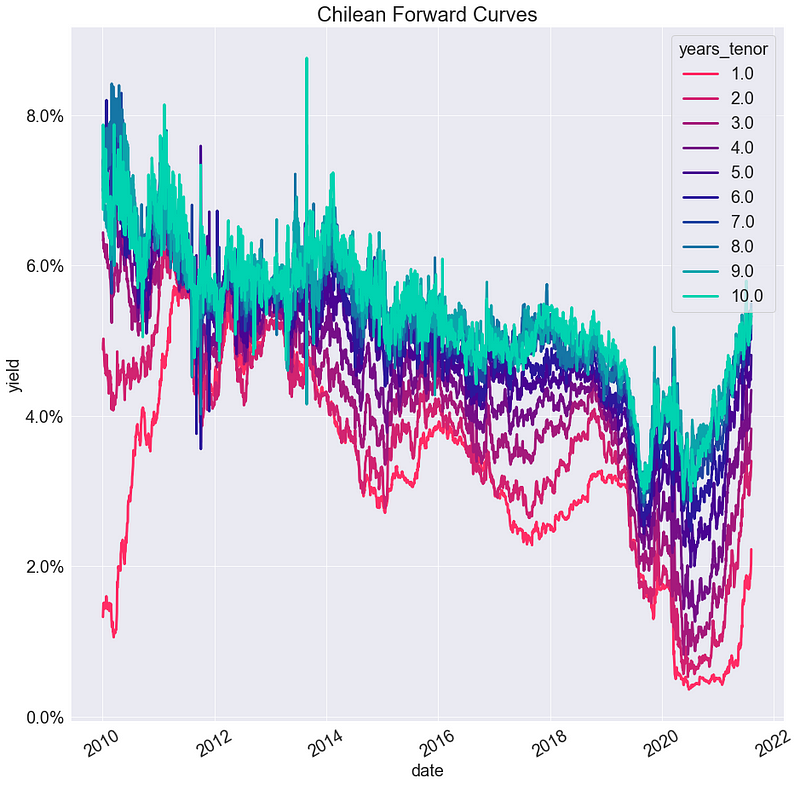
Haciendo lo anterior, se soluciona el problema de representar los datos de varias fechas, pero todavía es difícil hacerse una buena idea de cómo evolucionan las curvas.
PCA al rescate:
Por fortuna, existe el Análisis de Componentes Principales (PCA por sus siglas en inglés): un algoritmo de reducción de dimensionalidad que nos permite aproximar una curva dada por la suma ponderada de unos pocos componentes. Esto nos permite visualizar lo que pasa con la curva a través de la evolución de los pesos de dicha ponderación.
PCA descompone cada curva en 3 partes, según la siguiente fórmula:

- Una curva promedio, en torno a la cual todas las curvas oscilan.
- Componentes (C_i) multiplicados por sus respectivos pesos (W_i), que caracterizan los ajustes en torno a la curva promedio que tiene cada curva. En este artículo utilizaremos los primeros 3 componentes de PCA: nivel, pendiente y curvatura.
- Un error que se comete al aproximar una curva completa mediante sólo 3 componentes. Siempre que este error sea pequeño, PCA dará una buena caracterización de la curva.
Si es que deseamos sintetizar reconstruir la curva a partir de PCA, simplemente utilizamos la fórmula de arriba, ignorando el término de error.
Vamos a ver cómo se comporta cada una de estas partes para el caso de nuestro conjunto de datos.
0. PREPARACIÓN DE DATOS Y PCA
Para PCA, empezamos por cambiar los datos de curvas forward a formato ancho.
dfRatesWide = dfRatesLong.pivot(columns="years_tenor",
index="date",
values="yield")
dfRatesWide.tail(20)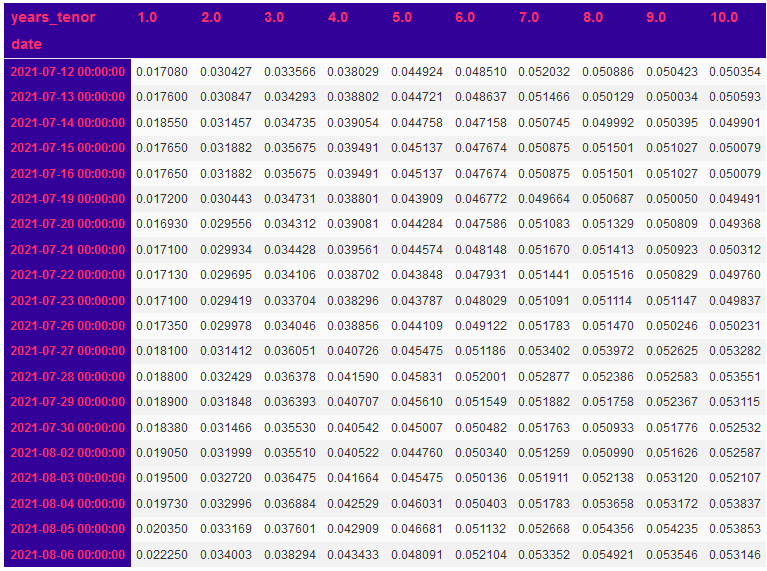
Una vez hecho esto, procedemos a efectuar el PCA con 3 componentes.
pca = PCA(n_components=3)
pca.fit(dfRatesWide.dropna())1. CURVA PROMEDIO
dfMean = pd.Series(pca.mean_,
name="yield",
index=dfRatesWide.columns)
dfMean = dfMean.reset_index()
g = sns.lineplot(data = dfMean,
x="years_tenor",
y="yield",
color = "black",
linewidth=4)
_ = g.yaxis.set_major_formatter(PercentFormatter(1))
_ = g.set_title("Forward Curve Mean")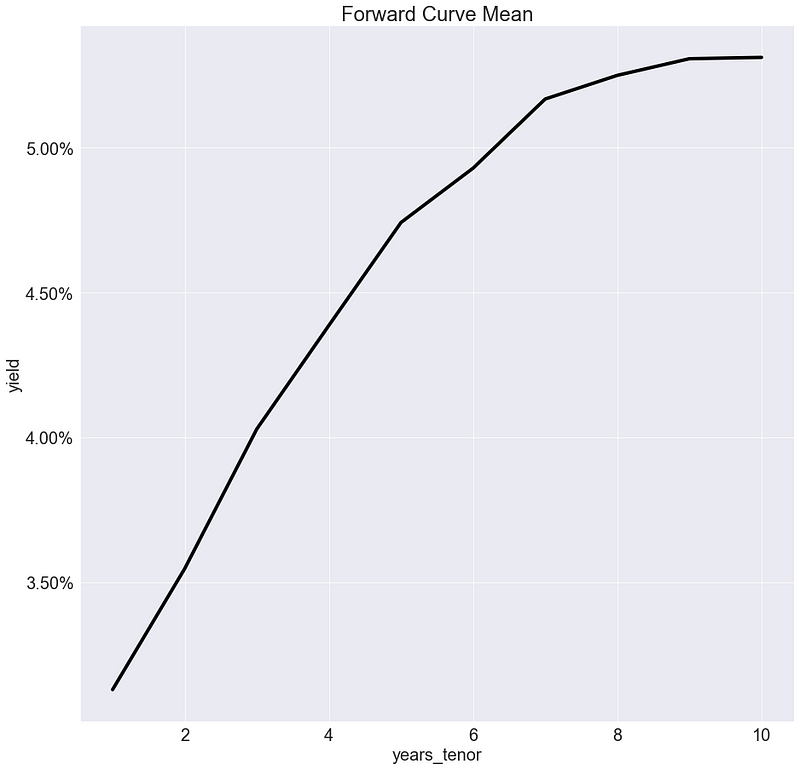
El promedio nos brinda información sobre cuál es la forma típica de la curva. Se observa claramente que las tasas de interés tienden a crecer con el tenor, y que la curva en promedio es cóncava.
2. COMPONENTES Y PESOS
Ésta es la parte de donde el PCA logra extraer la mayor información.
Para asegurarnos de que los componentes tengan la forma correcta (nivel positivo, pendiente ascendiente y curvatura convexa) y sea fácil interpretarlos, escribimos el siguiente código:
weights = pca.transform(dfRatesWide.dropna())
alternating = np.empty(shape=(weights.shape[1],))
alternating[::2] = 1
alternating[1::2] = -1
signs = np.sign(pca.components_[:, 0])*alternating
2.1 COMPONENTES (C_i)
Los componentes nos dicen las formas más habituales que tienen los cambios en la curva de tasas, y por lo tanto la mejor forma de caracterizar dichos cambios.
componentColumns = ["level (C1)",
"slope (C2)",
"curvature (C3)"]
dfComponents = pd.DataFrame(pca.components_.T*signs[None, :],
columns=componentColumns,
index=dfRatesWide.columns)
dfComponents = dfComponents.melt(ignore_index=False,
var_name="component",
value_name="value")
############
g = sns.lineplot(data = dfComponents,
x="years_tenor",
y="value",
hue="component"
)
g.hlines(y=0,
xmin=0.25,
xmax=10,
linewidth=4,
color="black")
_ = g.set_title("Forward Curve Components")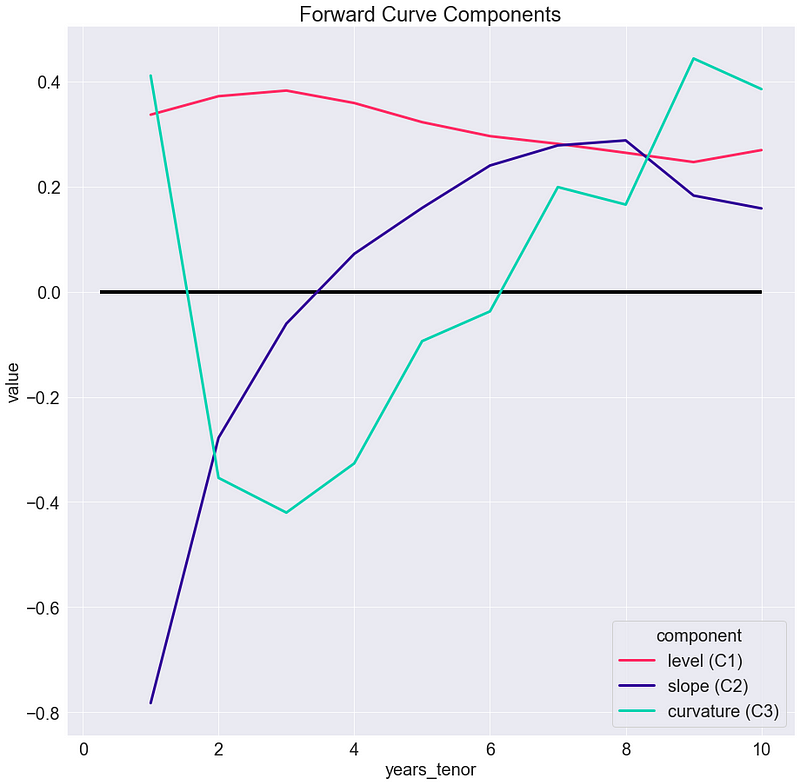
Podemos observar 3 tipos de cambios de curva con respecto al promedio:
- El componente de nivel nos indica cambios de aproximadamente la misma magnitud en todas las tasas
- El componente de pendiente nos indica caídas en tasas cortas (hasta 3 años) y subidas en tasas largas (4 años en adelante)
- El componente de curvatura nos indica caídas en tasas entre 2 y 6 años, junto con subidas en el resto de las tasas
2.2 PESOS DE LOS COMPONENTES (W_i)
Los pesos nos dicen cuánto de cada componente hay en una curva en particular: si las tasas están demasiado altas o bajas; si la curva está demasiado empinada, plana o invertida; etc. También nos permite caracterizar fácilmente la trayectoria de la curva a través del tiempo.
weightColumns = ["level (W1)",
"slope (W2)",
"curvature (W3)"]
dfWeights = pd.DataFrame(weights*signs,
columns=weightColumns,
index=dfRatesWide.dropna().index)
dfWeights = dfWeights.melt(ignore_index=False,
var_name="component",
value_name="weight")
############
g = sns.lineplot(data=dfWeights,
x="date",
y="weight",
hue="component")
_ = g.hlines(y=0,
xmin=dfWeights.index.min(),
xmax=dfWeights.index.max(),
linewidth=4,
color="black")
_ = g.yaxis.set_major_formatter(PercentFormatter(1))
_ = g.set_title("Forward Curve Component Weights")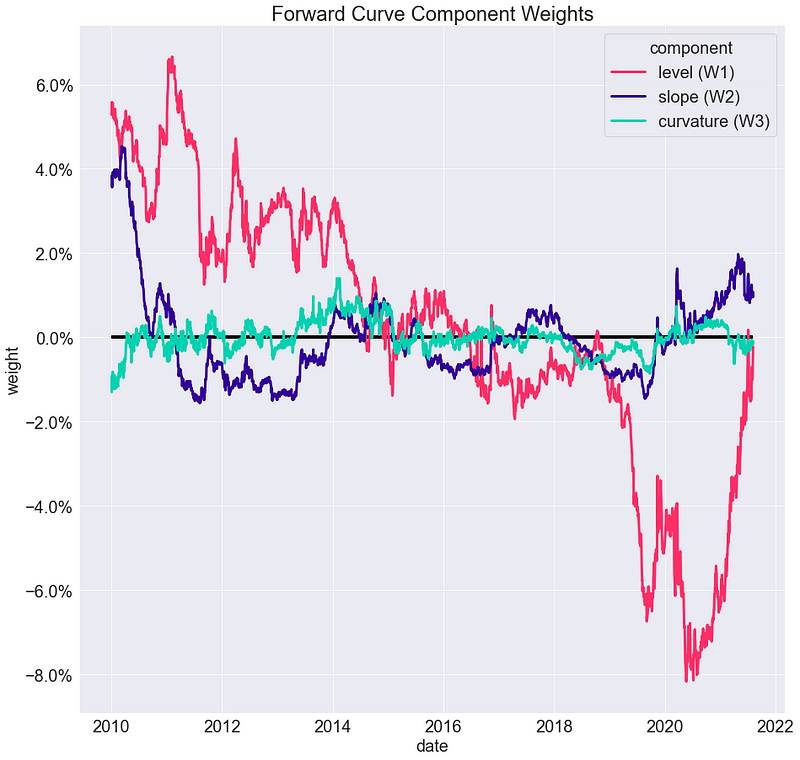
Podemos observar:
- Viendo el primer componente (nivel): las tasas han mostrado una tendencia a disminuir, con una fuerte caída durante 2019. También se observa una drástica subida durante 2021
- Viendo el segundo componente (pendiente): la curva estaba bastante empinada a principios de 2010, después de lo cual se aplanó en gran medida
- Viendo el tercer componente: no parecen haber cambios significativos en los últimos 10 años
3. ERRORES Y VARIANZA EXPLICADA
Queda una pregunta por responder: ¿Son suficientes 3 componentes para caracterizar una curva? ¿Hay fenómenos que no se están caracterizando bien y necesitamos más componentes? ¿Podemos caracterizar las curvas con aún menos componentes?
Para responder a estas preguntas, podemos referirnos a la varianza total de los datos. Cada componente explica un porcentaje de esta varianza total. Si con nuestros 3 componentes somos capaces de explicar un alto porcentaje de la varianza (digamos, más de un 95%), podemos afirmar que PCA nos da una descripción satisfactoria de las curvas y el error que cometemos con esta aproximación es pequeño.
explainedVarianceIndex = ["level",
"slope",
"curvature"]
dfExplainedVarianceRatio = pd.Series(pca.explained_variance_ratio_,
name="explained_variance",
index=explainedVarianceIndex)
dfExplainedVarianceRatio.index.name="component"
dfExplainedVarianceRatio = dfExplainedVarianceRatio.reset_index()
dfExplainedVarianceRatio.loc[3] = ["error",
1 - pca.explained_variance_ratio_.sum()]
dfExplainedVarianceRatio["explained_variance"]*=100
############
g = sns.barplot(data = dfExplainedVarianceRatio,
x = "component",
y = "explained_variance")
_ = g.yaxis.set_major_formatter(PercentFormatter(1))
_ = g.set_title("Explained Variance Percentage by Component")
for index, row in dfExplainedVarianceRatio.iterrows():
evp = row.explained_variance
g.text(index,
evp,
"{:.1%}".format(evp),
color="black",
ha="center")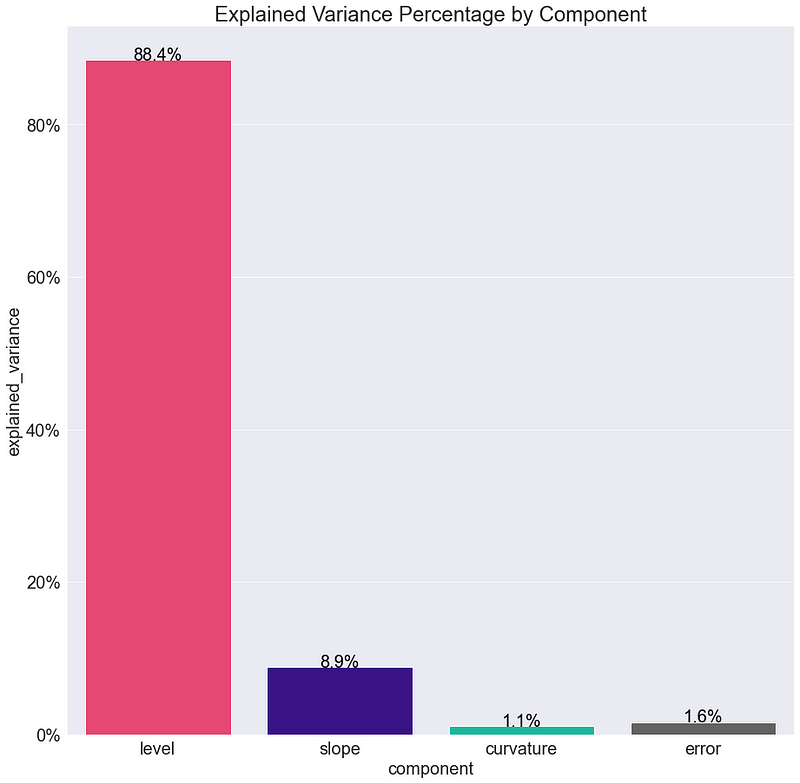
Como podemos ver en el gráfico, ¡los 3 componentes explican un 98.4% de la varianza!
De hecho, habría sido suficiente con utilizar tan solo los primeros 2 componentes: nivel y pendiente.
Acabamos de ver cómo utilizar PCA para visualizar y caracterizar con un alto nivel de precisión las curvas de tasas forward a 1 día del mercado chileno.
Sin embargo, hay un par de salvedades a considerar en el análisis:
- Con respecto a PCA, si queremos caracterizar las curvas actuales, las curvas recientes son más relevantes que las del pasado lejano. PCA le da la misma relevancia a todas las curvas.
- Con respecto a los datos, el Banco Central de Chile fija la tasa de interés corta 8 veces al año. Entre estas fijaciones de tasa, la tasa de interés permanece fija. Esta información no se utiliza en nuestro análisis. También está el hecho de que solamente utilizamos tasas forwards con tenors de entre 1 y 10 años, cuando el mercado tiene precios de forwards de tenors más cortos y más largos también.
En la API de Pacífico tenemos un análisis de PCA modificado que toma en cuenta estos factores.
Conoce todas nuestras publicaciones en Medium y síguenos para más información haciendo clic aquí
